

Voice Recognition
Background
Suppose an advertising team on Facebook is interested in identifying a person’s gender from an audio clip in order to increase the effectiveness in advertisements, and the engineer team has preprocessed and transformed the data into various formats. My task is to implement an algorithm that is able to classify whether the clip contains a male voice or a female voice. The dataset is available at Kaggle, and the python file is available at my Github page.
Data Exploration
Checking whether I read the data correctly and whether there are any NA values.
data.head(2)
data.isnull().sum() # alternative: data[data.isnull().any(axis=1)]
data['label'].value_counts() # there are 1584 male voices and 1584 female voices.
The dataset is imported correctly and there are no NA values. The dataset has a total of 3168 rows and 21 columns, with male clips and female clips equally distributed. To visualize how genders differ from each other, I generated several graphs using features like centroid and mean frequency. The more distinct they are, the easier it is to train a machine learning algorithm.
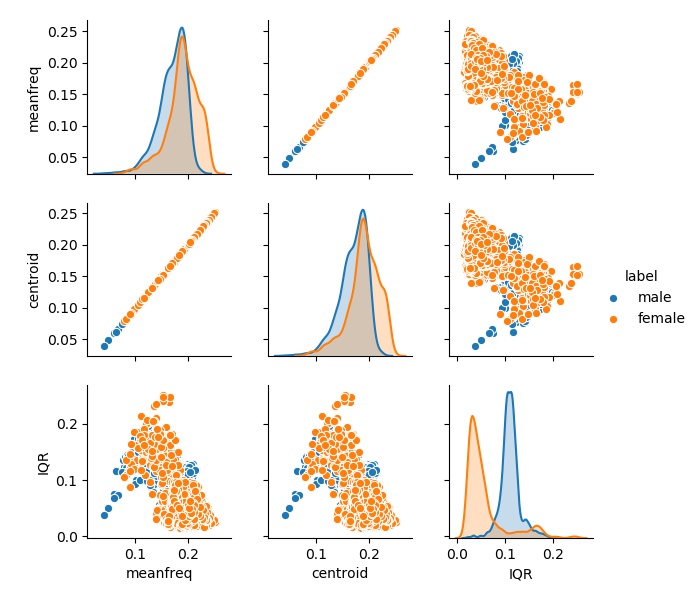
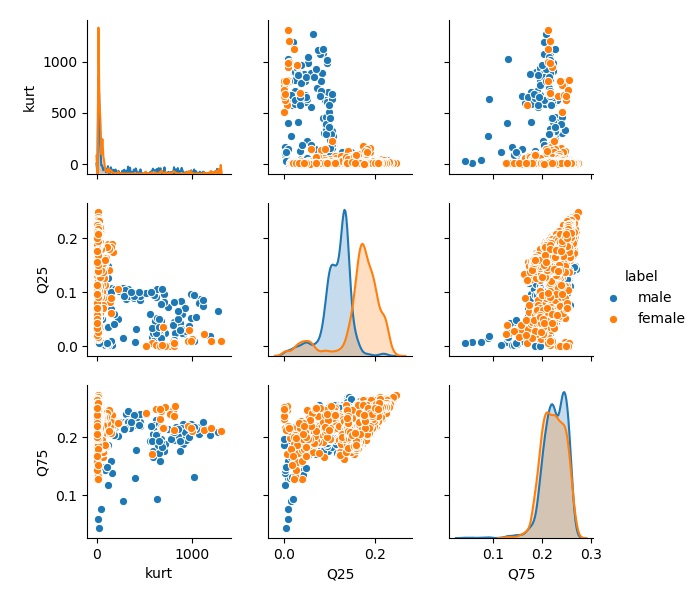
In the graphs above, there are clear differences in distribution between male and female in several features, such as IQR and Q25
Data Preprocessing
It is important to format the dataset before passing it to the machine learning model. The code I run below is applicable for most supervised learning algorithm:
- Turn the label into numeric values
- separate the label from the features
- Data Standardization
Turn the label into numeric value_counts
# Note that you can also use get_dummies from pandas
data = data.replace({'label': {'male': 1, 'female' :0}})
separate the labels from the features
label = data['label']
features = data.drop('label', axis = 1)
Data Standardization
Standardizing data allows machine learning models to treat each feature equally. Data Standardization is a good practice as it neutralizes variables that have large values. It can also minimize the risk of one feature from being too dominant compared to others in a machine learning model. There are several methods to achieve this goal, such as transforming feature’s range to 0 and 1 or standardizing features by removing the mean and scaling to unit variance. In this project, I will standardize the data by applying StandardScaler to each column: each attribute will have mean of 0 and standard deviation of 1. In addition, I also use train_test_split from sklearn in order to split the data into a training set and a test set, with 90% of the data as the training set, and the remaining 10% as the test set.
scaler = StandardScaler()
features = scaler.fit_transform(features)
# split the data into training set and test set
x_train, x_test, y_train, y_test = train_test_split(features, label, test_size = 0.1, random_state = 1 )
Model Training & Tuning
After splitting the data into training and test set, I used support vector machine algorithm in order to predict Male/Female voices. In addition, I calculated the accuracy score in order to evaluate the performance of the model. Accuracy score compares each prediction with the actual result and returns the number of correct predictions over the number of predictions. If the model predicted everything correctly, the accuracy score will be 1. The higher the accuracy is, the better the performance. Accuracy is a useful metric in this case because male and female have the same amount of rows.
clf = SVC()
clf.fit(x_train, y_train)
predictions = clf.predict(x_test)
I will be using k-fold cross-validation in order to prevent the data from overfitting. For model tuning, I will adjust C and Gamma in order to find out the best parameters for this data; specifically, I will generate a graph for ‘C’ and see how large ‘C’ is for the best accuracy.
# create an object for 10-fold cv
k_fold = KFold(n_splits=10, random_state=1, shuffle=True)
# scorer for cv, accuracy_score in this case
scorer = make_scorer(accuracy_score)
C_range = list(range(1, 100))
c_tuning_score = []
for c in C_range:
model = SVC(C=c)
cv_scores = cross_val_score(model, x_train, y_train, cv=k_fold, scoring=scorer)
c_tuning_score.append(cv_scores.mean())
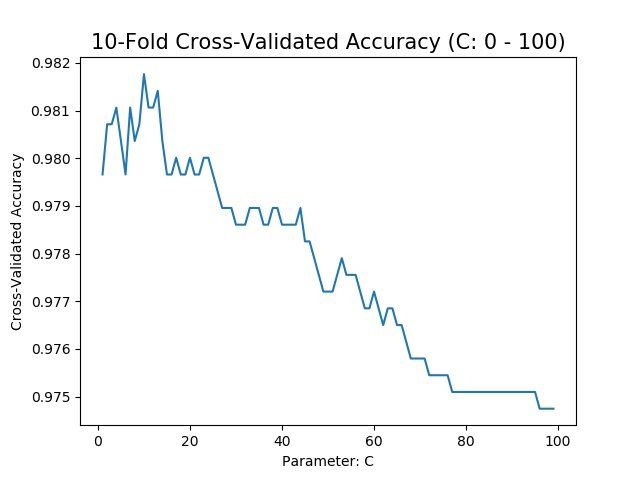
When using the code above, the model performs best when C is in between 5 and 15. To find out the best estimate for C, I zoom in the graph and locate the exact value of C that give me the maximum of accuracy.
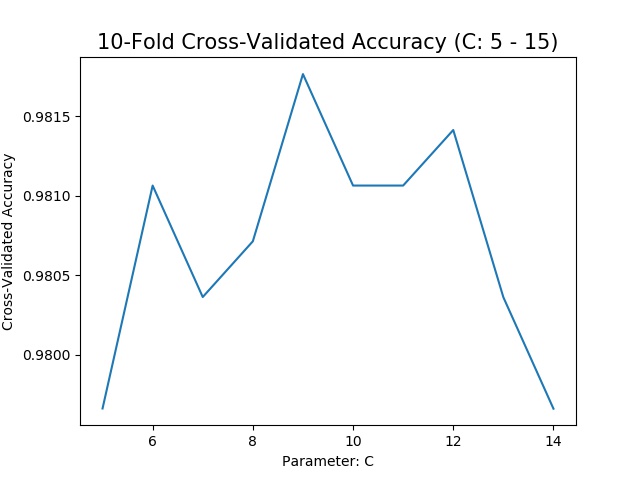
It turns out that the model performs the best when C is 9. Now repeat the same steps above, but with Gamma as the parameter. Here I simplify the method a bit by adjusting gamma as (0.0001, 0.001, .01, .1, 1, 10, 100). It turns out the best Gamma is 0.05. As a result, the best hyperparameters for SVM for this data is C = 9 and gamma = 0.05.
Finalize the model
Before I make any prediction on the test set, I decided to run a k-fold validation in order to make sure the model is not overfitting. It turns out that the average accuracy for a 10-fold validation is 98.2%.
clf = SVC(C=9, gamma=0.05)
k_fold = KFold(n_splits=10, random_state=3, shuffle=True)
scorer = make_scorer(accuracy_score)
cv_scores = cross_val_score(clf, x_train, y_train, cv=k_fold, scoring=scorer)
cv_scores.mean() # the k-fold cv average accuracy is 98.17%
It is finally the time to plug the model in to the test set.
clf.fit(x_train, y_train)
predictions = clf.predict(x_test)
accuracy_score(y_test, predictions) #accuracy: 99.05% on test set
The SVM model performed exceptionally well, with 99.05% accuracy on our test set! While this is a decent model, there are some potential improvements that I could have tried when tuning it, such as kernel = ‘linear’ or ‘poly’. I only used ‘rbf’ in this project, but I am still able to get 99% accuracy for my test set.
Implementation
Not only can the model be used in advertising team to increase the effectiveness in finding the right target to sell their products, but it can also be used in customer service team. For example, they can predict whether the voice of a complaint is male or female and construct an analysis on gender regarding whether one gender tends to have more complains than the other. Having this model is handy as it save the company tons of resources and time.