

Fruit Image Recognition
Introduction
A company is planning to build an app that helps the general public to know more about nutritional values, specifically fruits. They are very impressed by Google Lens and want to build one on their own. While the database team is building a nutritional database to show nutrition values on different fruits, my task as a data scientist is to develop a model that is able to identify what fruit is showing in an image.
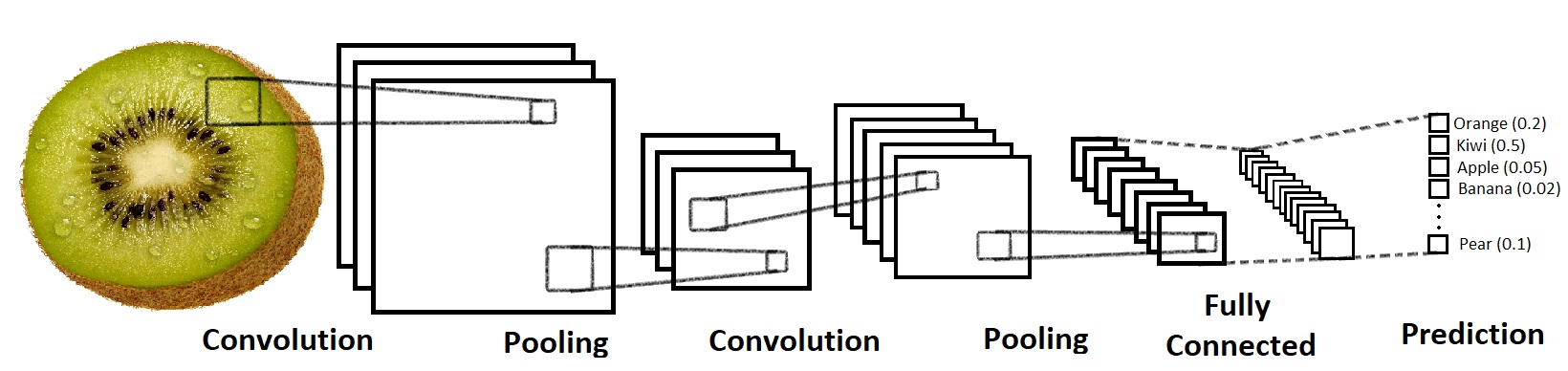
Convolutional Neural Network is the perfect solution to this problem.
Human identify objects by analyzing their color, shape, and texture. Convolutional neural network is capable of completing such task, because it is able to preserve spatial relationship between pixels, which ultimately isolating color, shape, and texture as independent factors. it then can predict what fruit is in the image based on the factors identified by CNN.
Data Preprocessing
I gathered 22 types of fruit images on Google, each type has its own folder and has approximately 100 images. Given this is a relatively small dataset, I decided to implement data augmentation in order to increase the amount of examples to train the model. There are four forms for each image: its original form, a flipped version, rotated 90 degrees, and rotated 270 degrees. I also resized all images to 100x100 pixels in order to increase the training speed performance, and divide all pixels by 255 in order to limit their ranges to 0 and 1.
def process_image(img_path, img_list, label_list, fruit_name, dim):
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
image = cv2.resize(image, (dim, dim)) # resize to dim*dim (dim=100 in my case)
img_list.append((image / 255.).tolist())
img_list.append((np.flipud(image)/ 255.).tolist()) # adding a flipped form
img_list.append((rot(image, 90) / 255.).tolist()) # adding a rotated image (90 degrees)
img_list.append((rot(image, 270) / 255.).tolist()) # adding a rotated image (270 degrees)
label_list += [fruit_name]*4 # add those fruit labels
Model Tuning
I will be implementing a pre-trained model, VGG16, in this project. VGG16 is a CNN architecture that is considered to be an excellent vision model, and it generally performs well on object classifications. Prior to implementing VGG16, I have already tried out different models, such as artificial neural network and self-built CNN, but VGG16 outperformed other models and seemed to perform the best.
At the end of the VGG16 model, I will be adding a fully connected layer (ReLU) as well as two dropout layers before and after the fully connected layer. I then close the model by adding a softmax layer with 22 nodes, which equal the number of fruit types. Adding dropout layers can reduce the model to overfit by preventing co-adaptation on data. In my case, the dropout rate is 20%, meaning the model will be randomly blocking 20% of the nodes before and after the fully connected layer when training the model. The image below shows the beginning and the last layers of the model.
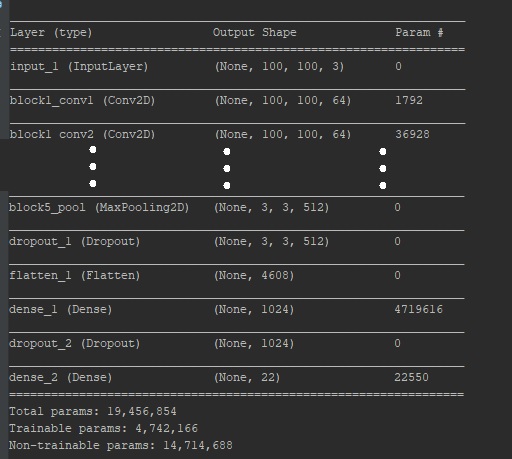
I will be using categorical_crossentropy as my loss function and accuracy as my metric to evaluate model’s performance. categorical_crossentropy increases as the predicted probability diverges from the actual label. In other words, we want to minimize categorical_crossentropy to increase the predictive power of the model. Moreover, I will use accuracy as my metric to evaluate the model performance. The accuracy is calculated by the number of correct prediction / the number of total prediction * 100%. The higher the accuracy is, the better the model performance. I am also setting the benchmark to be guessing the result at random. In other words, there is a 4.5% chance of getting the fruit correctly when guessing randomly.
In addition, I set the model to train for 50 epochs, which should be enough for most cases. The training process will stop when the accuracy on the validation set doesn’t improve for five epochs. For example, if the accuracy was 80% on 23th epochs and the accuracy did not scored higher than 80% for the next five epochs, the model would stop training and return the model with 80% accuracy.
I am going to use Grid Search in order to find the best parameters for the model by adjusting the following:
- the number of trainable VGG16 layers (None vs. the last 5 layers)
- learning rates (0.01 vs. 0.001 vs. 0.0001)
- RMSprop vs. SGD optimizer
The result is shown below:

Note: In addition to the result above, I also tested out learning rate of 0.00001 on RMS with last 5 trainable layers, the result was 78.72%.
The best parameters for this model is learning rate = 0.0001, RMS, and the last five layers are trainable, which achieved more than 80% of accuracy.
Let’s throw this model to some real-life photos I personally took and see how the model would handle:




In the above images, the model correctly predicted apple, banana, and the second orange (bottom right). It predicted the first orange (bottom left) as lemon. In fact, the first orange does look like a lemon, but we have seen enough oranges to learn that not all oranges have orange color. The model took color into consideration, and the oranges from the training sets mostly are orange color, which led the model to think oranges must have orange color. That might be one of the reasons why it thought the fruit in the image was a lemon instead of an orange.
Conclusion
In this post, I discussed how we can apply CNN models to identify fruits in an image, even if you have a limited dataset. Data augmentation is extremely useful when your model needs to recognize a label that has limited resources. Model tuning is also an important part of building neural networks. As shown above, different parameters could have very different outcomes even if we just adjust learning rate alone. Choosing the best optimizer/ learning rate and adjusting the best number of trainable layers are just one of the many steps in finding the best model for this data, and I believe the model could still be improved.